
数据,如同繁星点点,在广袤的信息宇宙中闪烁着独特的光芒,每一缕数据的波动,都或许隐藏着市场的秘密、用户的需求或是未来的走向,在这个充满变数的时代,数据分析成为了连接未知与已知的桥梁,作为一名资深数据分析师,我深知数据的潜力与价值,也明白在海量信息中寻找那一把开启智慧之门钥匙的挑战,就让我们一起踏上这场由“澳门一码一肖一特一中五码必中”这一主题所引发的探索之旅,用科学的分析方法,拨开迷雾,揭示背后的逻辑与真相。
一、数据收集:编织数字的经纬
一切分析的起点在于数据本身,对于“澳门一码一肖一特一中五码必中”这样的特定话题,首要任务是明确数据源,这可能包括但不限于历史开奖记录、玩家投注行为数据、相关论坛讨论热度等多维度信息的集合,通过API接口获取官方发布的开奖结果,利用网络爬虫技术搜集社交媒体上的公开言论,甚至合作获取特定平台的用户匿名化操作日志,确保数据的全面性和准确性,是构建可靠分析模型的基石。
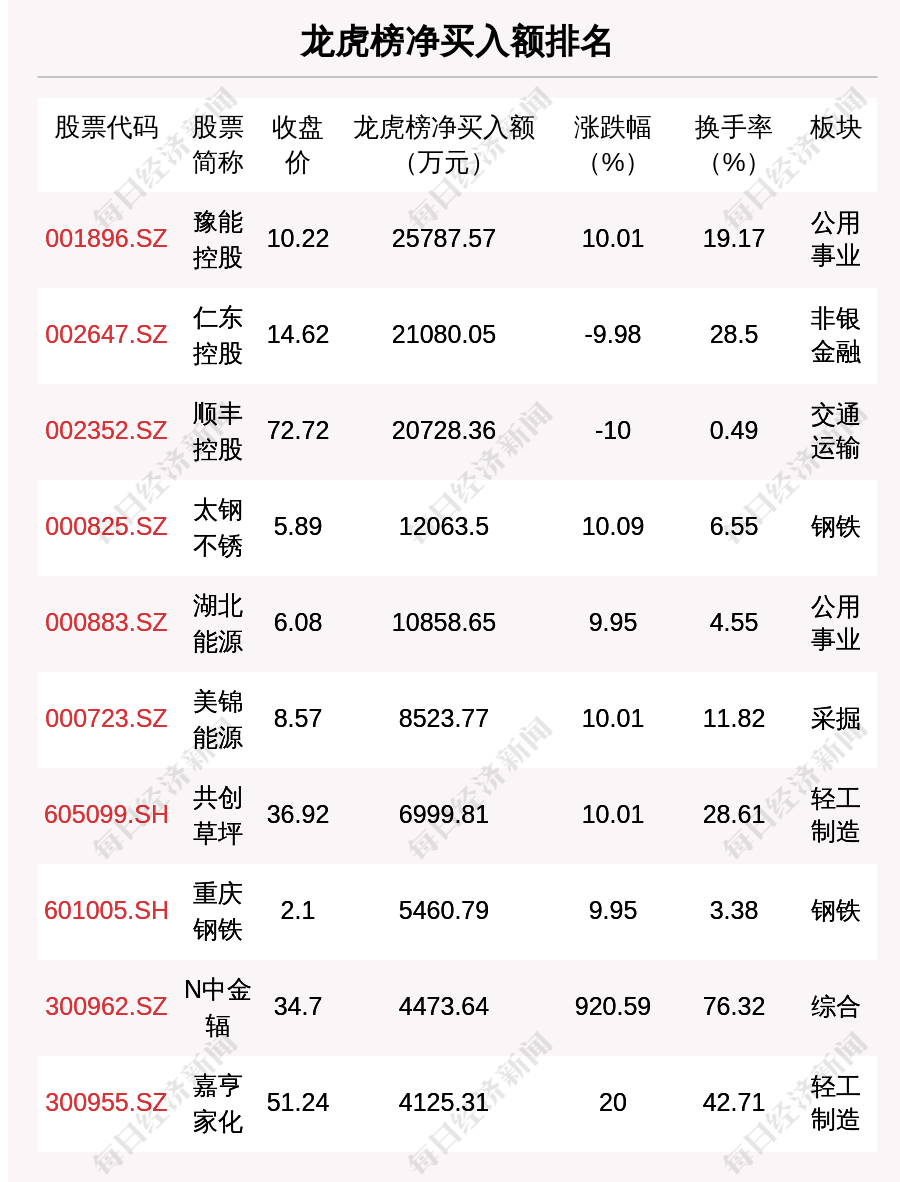
以历史开奖记录为例,我们可以构建一个包含期号、开奖号码、各号码出现频率等字段的数据表,假设我们收集了过去一年的记录,得到了如下简化示例:
| 期号 | 开奖号码 | A | B | C | D | E | F | G |
| 001 | ABCD5 | 1 | 2 | 3 | 4 | 5 | ||
| 002 | DEFG6 | 6 | 7 | |||||
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
A-G代表不同位置上的单个号码(为了简化,此处仅以字母代替实际数字),"-"表示该位置未出现对应字母所代表的号码,通过这种方式,我们将非结构化的开奖结果转化为结构化数据,便于后续处理。
二、数据清洗:剔除杂质,提炼精华
原始数据往往充斥着噪声与异常值,直接使用可能导致分析结果偏差,数据清洗成为不可或缺的一环,针对上述数据集,我们需要执行以下步骤:
缺失值处理:检查每个字段是否存在大量空缺,若某位置长期未出现某号码,可考虑删除该记录或采用均值/中位数填补。
异常值检测:利用统计方法识别出偏离正常范围的数据点,如极端高频出现的号码组合,需进一步调查是否为人为操纵或其他因素导致。
格式统一:确保所有数据遵循相同标准,比如日期格式、数值单位等,减少因格式不一致引入的错误。
经过清洗后的数据更加纯净,为深入分析奠定了坚实基础。
三、探索性数据分析:初探端倪

初步了解数据分布特征是关键步骤之一,运用统计学工具,如Python中的Pandas库和Matplotlib库,我们可以快速绘制出号码出现频次的直方图、折线图等可视化图表,直观展示哪些号码更常出现,以及它们随时间的变化趋势。
import pandas as pd
import matplotlib.pyplot as plt
假设df是已加载并清洗好的数据框
frequency = df.iloc[:, 1:].apply(pd.value_counts).fillna(0)
plt.figure(figsize=(10, 6))
for col in frequency.columns:
plt.plot(frequency.index, frequency[col], label=col)
plt.title('号码出现频次')
plt.xlabel('号码')
plt.ylabel('频次')
plt.legend()
plt.show()这段代码帮助我们生成了一张图表,展示了各个号码在不同位置的出现频率变化情况,通过观察图表,可能会发现某些号码在特定时间段内频繁出现,或者存在某种周期性规律。
四、高级分析与建模:挖掘深层关联
基于初步探索的结果,我们可以进一步运用机器学习算法来预测未来可能出现的号码组合,常见的方法包括逻辑回归、决策树、随机森林乃至深度学习模型,利用Scikit-Learn库,我们可以构建一个简单的随机森林分类器:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
准备特征和标签
X = df.iloc[:, 1:].values # 特征矩阵
y = df['开奖号码'] # 假设'开奖号码'列包含了目标信息
划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
训练模型
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
预测与评估
y_pred = clf.predict(X_test)
print(f'准确率: {accuracy_score(y_test, y_pred)}')虽然实际应用中预测具体号码极具挑战性,但此类模型可以帮助我们识别出影响开奖结果的关键因素,从而间接提高选号策略的有效性。

五、结论与建议:洞察未来,指导实践
通过一系列严谨的数据分析流程,我们对“澳门一码一肖一特一中五码必中”的现象有了更为深刻的理解,重要的是认识到,尽管数据分析能提供一定的概率优势,但彩票本质上仍是一种概率游戏,不存在绝对的“必中”法则,建议彩民保持理性态度,将购彩视为一种娱乐方式而非赚钱手段,同时关注资金管理,避免过度投入。
对于数据分析工作而言,持续优化模型、探索新的特征变量、加强跨领域知识的融合应用将是提升预测精度的关键路径,每一次分析都是向真理靠近的一步,而真正的智慧,在于不断学习与适应这个瞬息万变的世界。







 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号